Inmigración - Donde Viven? - Parte 2
Esta publicación es la continuación de una publicación anterior y busca construir un modelo de clasificación de aprendizaje automático para predecir si un inmigrante que llegó a Santiago de Chile en 2019 vivía en el Sector Oriente de la ciudad al llegar.
2) Paquetes
Se utilizan los siguientes paquetes en esta publicación.
library(dplyr)
library(caret)
library(modelr)
library(forcats)
library(caTools)
library(knitr)3) Sector Oriente
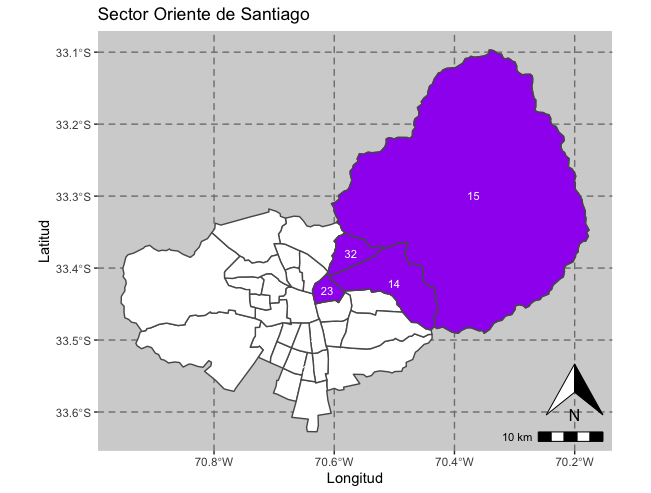
Como se explicó anteriormente, el Sector Oriental contiene las comunas de Providencia, Las Condes, Vitacura, y Lo Barnechea y se ubica al noreste de la ciudad. Estas comunas se consideran las más ricas de la ciudad y se identifican en el siguiente mapa.
4) Distribución de inmigrantes
El siguiente mapa muestra la distribución de todos los inmigrantes que arribaron a Santiago en 2019. Cabe señalar que los datos utilizados solo se refieren a la comuna de residencia cuando un inmigrante solicitó su visa. Por lo tanto, es posible que desde entonces se hayan mudado a un sector diferente de la ciudad. La siguiente tabla detalla qué etiquetas responden a qué comunas.

etiquetas <- read.csv('lables.csv')
etiquetas## X nombre_comuna labels
## 1 1 Santiago 1
## 2 2 Cerrillos 2
## 3 3 Cerro Navia 3
## 4 4 Conchalí 4
## 5 5 El Bosque 5
## 6 6 Estación Central 6
## 7 7 Huechuraba 7
## 8 8 Independencia 8
## 9 9 La Cisterna 9
## 10 10 La Florida 10
## 11 11 La Granja 11
## 12 12 La Pintana 12
## 13 13 La Reina 13
## 14 14 Las Condes 14
## 15 15 Lo Barnechea 15
## 16 16 Lo Espejo 16
## 17 17 Lo Prado 17
## 18 18 Macul 18
## 19 19 Maipú 19
## 20 20 Ñuñoa 20
## 21 21 Pedro Aguirre Cerda 21
## 22 22 Peñalolén 22
## 23 23 Providencia 23
## 24 24 Pudahuel 24
## 25 25 Quilicura 25
## 26 26 Quinta Normal 26
## 27 27 Recoleta 27
## 28 28 Renca 28
## 29 29 San Joaquín 29
## 30 30 San Miguel 30
## 31 31 San Ramón 31
## 32 32 Vitacura 325) Datos
La idea de esta sección es crear un modelo de clasificación para predecir en qué comuna vivían los inmigrantes cuando llegaron a Santiago. Los datos utilizados son el marco de datos visas2019STG que se preparó en la parte 1.
visas2019STG <- read.csv("visas2019STG.csv")6) Preparación del modelo
Se llevan a cabo los siguientes procesos para preparar los datos para el modelo.
6.1) Selección de variables y variable del sector oriente
Primero se eligen las variables relevantes.
visas2019STGfilter <- visas2019STG %>% select(SEXO, PAÍS, ACTIVIDAD, PROFESIÓN, ESTUDIOS, nombre_comuna, AÑO, MES, Age)En segundo lugar, se crea una nueva variable binomial para determinar si un inmigrante vivía en el Sector Este. Dentro de esta variable 1 representa un inmigrante que vivía en el Sector Este, y 0 representa un inmigrante que vivía en un sector diferente de la ciudad.
visas2019STGfilter$SECTOR_ORRIENTE <- if_else(visas2019STGfilter$nombre_comuna == 'Providencia', 1,
if_else(visas2019STGfilter$nombre_comuna == 'Las Condes', 1,
if_else(visas2019STGfilter$nombre_comuna == 'Vitacura', 1,
if_else(visas2019STGfilter$nombre_comuna =='Lo Barnechea', 1, 0))))6.2) One Hot Encoding
En tercer lugar, se realiza One Hot Encoding. Este es un proceso mediante el cual convertir variables categóricas en una estructura que es más fácil de calcular. Cuando se aplica One Hot Encoding a una variable en particular, se crean nuevas columnas para cada clase de la variable original. Para cada columna de clase se registra un 1 para todas las observaciones que tienen esa clase, con un 0 para todas las que no.
Se realiza One Hot Encoding para las variables de Sexo, Actividad y Estudios.
Sex
model_matrix(visas2019STGfilter, SECTOR_ORRIENTE~SEXO-1)
visas2019STGfilter <- cbind(visas2019STGfilter, model_matrix(visas2019STGfilter, SECTOR_ORRIENTE~SEXO-1))Activity
model_matrix(visas2019STGfilter, SECTOR_ORRIENTE~ACTIVIDAD-1)
visas2019STGfilter <- cbind(visas2019STGfilter, model_matrix(visas2019STGfilter, SECTOR_ORRIENTE~ACTIVIDAD-1))Studies
model_matrix(visas2019STGfilter, SECTOR_ORRIENTE~ESTUDIOS-1)
visas2019STGfilter <- cbind(visas2019STGfilter, model_matrix(visas2019STGfilter, SECTOR_ORRIENTE~ESTUDIOS-1))6.3) Países a continentes
En total hay 75 nacionalidades en los datos. Para facilitar su cálculo, se crea una nueva variable, agrupando las nacionalidades en continentes. A continuación, se realiza One Hot Encoding para esta variable.
visas2019STGfilter$continente <- fct_collapse(visas2019STGfilter$PAÍS, Europe = c('Alemania', 'Austria', 'Bélgica', 'Bulgaria', 'Croacia', 'Dinamarca', 'Eslovaquia', 'España', 'Finlandia',
'Francia', 'Grecia', 'Holanda', 'Hungría', 'Inglaterra', 'Irlanda', 'Italia', 'Lituania', 'Noruega',
'Polonia', 'Portugal', 'República Checa', 'República De Bielorrusia', 'República De Serbia',
'Rumanía', 'Rusia', 'Suecia', 'Suiza', 'Ucrania'), Africa = c('Angola', 'Camerún', 'Egipto', 'Marruecos', 'República de Congo', 'Sudráfica'),
Asia = c('Bangladesh', 'Corea del Sur', 'China', 'Filipinas', 'India', 'Indonesia', 'Irán', 'Israel', 'Japón',
'Jordania', 'Líbano', 'Malasia', 'Nepal', 'Pakistán', 'Palestina', 'Siria', 'Tailandia', 'Taiwan', 'Turquía'),
SouthAmerica = c('Argentina', 'Bolivia', 'Brasil', 'Colombia', 'Ecuador', 'Paraguay', 'Perú', 'Uruguay', 'Venezuela'),
CentralAmerica = c('Costa Rica', 'Cuba', 'El Salvador', 'Guatemala', 'Haití', 'Honduras', 'México', 'Nicaragua', 'Panamá','República Dominicana'),
NorthAmerica = c('Canadá', 'Estados Unidos'), Other = c('Otro país'),
Oceania = c('Australia', 'Nueva Zelanda'))visas2019STGfilter <- cbind(visas2019STGfilter, model_matrix(visas2019STGfilter, SECTOR_ORRIENTE~continente-1))7) Creando el modelo
Los datos se dividen en dos grupos. Uno es el grupo de entrenamiento con el 75% de las observaciones. El segundo es el grupo de ensayo con el 25% de las observaciones.
set.seed(1234)
split <- sample.split(visas2019STGfilter$SECTOR_ORRIENTE, SplitRatio = 0.75)
training_set <- subset(visas2019STGfilter, split == TRUE)
test_set <- subset(visas2019STGfilter, split == FALSE)training_set_cut <- training_set[,c(-1, -2, -3, -4, -5, -6, -7, -8, -9, -34)]
test_set_cut <- test_set[,c(-1, -2, -3, -4, -5, -6, -7, -8, -9, -34)]7.1) Entrenando el modelo
Un modelo lineal general se crea y se entrena con la siguiente sintaxis.
set.seed(1234)
classifier = glm(formula = SECTOR_ORRIENTE ~.,
family = binomial,
data = training_set_cut)El modelo se utiliza para hacer predicciones sobre los datos de ensayo. Una predicción de 1 representa un inmigrante en el Sector Oriente y una predicción de 0 representa un inmigrante en otra área de la ciudad. Se utiliza una matriz de confusión para evaluar la precisión del modelo.
set.seed(1234)
prob_pred <- predict(classifier, type = 'response', newdata = test_set_cut[,c(-1)])y_pred <- ifelse(prob_pred >= 0.5, 1, 0)cm <- confusionMatrix(factor(test_set_cut$SECTOR_ORRIENTE), factor(y_pred), positive = "1")
cm## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 22616 169
## 1 1617 262
##
## Accuracy : 0.9276
## 95% CI : (0.9243, 0.9308)
## No Information Rate : 0.9825
## P-Value [Acc > NIR] : 1
##
## Kappa : 0.2042
##
## Mcnemar's Test P-Value : <2e-16
##
## Sensitivity : 0.60789
## Specificity : 0.93327
## Pos Pred Value : 0.13944
## Neg Pred Value : 0.99258
## Prevalence : 0.01747
## Detection Rate : 0.01062
## Detection Prevalence : 0.07618
## Balanced Accuracy : 0.77058
##
## 'Positive' Class : 1
## 8) Análisis
La matriz de confusión compara los datos reales con los datos predichos para mostrar qué tan preciso es el modelo.
Se dan cuatro numeros:
SectorOrienteCorrecto = 262
SectorOrienteFalso = 1617
OtroSectorCorrecto = 22616
OtroSectorFalso = 169
totalobservaciones <- SectorOrienteCorrecto + SectorOrienteFalso + OtroSectorCorrecto + OtroSectorFalsoCon estos números se pueden calcular los cuatro valores siguientes:
- Accuaracy
- Precision
- Recall
- Kappa
Estos valores son importantes para analizar el éxito del modelo y se analizan a continuación.
8.1) Accuracy
El modelo tuvo un Accuracy del 92,76%. Esto significa que el modelo clasificó correctamente el 92,76% de los datos de ensayo.
Accuracy <- ((SectorOrienteCorrecto + OtroSectorCorrecto)/totalobservaciones)8.2) Precision
El modelo tiene un Precision del 13,94%. Esto significa que de todos los inmigrantes que se preveía que vivieran en el Sector Este, el 13,94% vivía realmente allí.
Precision <- SectorOrienteCorrecto/(SectorOrienteCorrecto+SectorOrienteFalso)8.3) Recall
El Recall del 60,79% significa que de los 431 inmigrantes que realmente vivían en el Sector Oriente el modelo correctamente predijo 60,79%.
Recall <- SectorOrienteCorrecto/(SectorOrienteCorrecto+OtroSectorFalso)8.4) Kappa
Uno de los problemas con los datos es que no están equilibrados. Solo 431 inmigrantes de los datos de ensayo vivían allí, lo que representa el 1,75%. Posteriormente, el modelo puede obtener fácilmente un alto Accuracy ya que podría predecir que todas las observaciones no viven en el Sector Oriente, y aún así obtendría un Accuracy del 98,25%.
Por lo tanto, el valor Kappa se puede usar para medir qué tan bien se desempeñó el modelo. El rendimiento de los modelos se compara con los resultados si el modelo se hubiera ejecutado al azar con los datos. El valor de Kappa está entre 0 y 1, y cuanto más cercano a 1 significa que el modelo es más preciso.
El modelo tiene un Kappa de 0,2042. Esto significa que el modelo clasificó los datos con una precisión un 20,42% mejor que la de una clasificación aleatoria. Un valor Kappa de entre 0,21 y 0,40 se considera razonable.
Se puede leer más sobre cómo calcular el valor de Kappa
9) Conclusión
En conclusión esta publicación ha creado un modelo de clasificación para clasificar si un inmigrante que llegó a Santiago en 2019 vivía en el Sector Oriente. Ha seguido la publicación parte 1 que preparó los datos y analizó la distribución de algunas nacionalidades en la ciudad. Cuando se utilizó el modelo en los datos de prueba, se obtuvo un Accuracy del 92,76% con un valor de Kappa de 0,2042, lo que sugirió que el modelo tuvo cierto éxito. Sin embargo, la Precision del 13,94% y el Recall del 60,79% sugieren que al modelo le resultó difícil clasificar correctamente a los inmigrantes del Setor Oriente. El modelo podría mejorarse con datos distribuidos de manera más equitativa y con diferentes tipos de modelos de clasificación probados. Estas opciones se explorarán en futuras publicaciones. Muchas gracias por leer esta publicación.